
Gensparkの安全性は本当に大丈夫?ビジネス導入へのリスク評価と対策法

2024年に登場したAI検索エンジン「Genspark」が、企業のデジタル変革を支援するツールとして注目を集めています。しかし、創業者が中国系大手企業Baidu出身であることや、データの海外保存が行われる可能性など、ビジネス利用におけるセキュリティリスクへの懸念も高まっているのが現状です。
実際に、サムスン電子では従業員がChatGPTに機密情報を入力した結果、情報漏洩リスクが発覚し生成AI利用を一時禁止する事態が発生しました。香港の多国籍企業では、AIを悪用した詐欺により38億円もの損失が発生するという深刻な事件も起きています。
本記事では、Gensparkの安全性について徹底的に分析し、企業が導入前に確認すべき重要なポイントを具体的に解説します。
- MainFunc社の信頼性とリスク評価
- 5つの主要セキュリティ懸念点
- Perplexity AI・Claude・ChatGPTとの機能比較
- 段階的導入アプローチによる安全な導入手順
- コンプライアンス要件と意思決定基準

Gensparkとは?運営会社の信頼性と安全性の現状

Gensparkは、2023年設立のMainFunc社が2024年6月にリリースしたAI検索エンジンです。質問に対してリアルタイムで「Sparkページ」を生成し、複数のAIモデルを活用した回答を提供する新しい仕組みを採用しています。
企業でのAI活用が急速に拡大する中、セキュリティ事故も相次いでおり、慎重な導入検討が求められています。
MainFunc社の企業概要とバックグラウンド
MainFunc社は元Microsoft、Google、Baiduの社員により2024年に設立された新興企業です。
共同創業者兼CEOのEric Jingは、Baidu Group元副社長およびXiaodu Technology元CEOで、AI研究開発に約20年従事してきました。

もう一人の共同創業者Kay ZhuはCTOとして、BaiduとGoogleでの豊富な技術経験を持ちます。創業チームが中国系大手IT企業出身者で構成されている点は、データ管理の透明性を評価する際の重要な要素となります。
パロアルト・シンガポール拠点の運営体制
同社はカリフォルニア州パロアルトに本社を置き、シンガポールにも拠点を設置しています。利用規約ではカリフォルニア州法が適用されると明記されており、法的管轄権は米国です。
ただし、複数国・地域での運営によりデータ処理の複雑性が増大しています。データがMicrosoft Azureに保存されると記載されていますが、具体的なサーバー所在地は非公開です。
資金調達状況と投資家からの評価

MainFunc社は2024年6月に6000万ドルのシード資金調達を完了し、企業価値2億6000万ドルと評価されました。このシードラウンドはシンガポール拠点のLanchi Venturesが主導しました。
2025年2月にはシリーズA資金調達で1億ドルを追加調達し、企業価値は5億3000万ドルに上昇しています。設立から短期間での高額調達は技術的実証よりも成長期待に基づく側面が強く、長期的継続性の評価には注意が必要です。
 ReAlice株式会社 AIコンサルタント
ReAlice株式会社 AIコンサルタントGensparkは複数AIモデルの融合による検索応答生成が特徴的で、従来の検索体験を刷新する設計思想が見られます。
Gensparkの安全性における主要な懸念点
新興企業による短期間での急成長サービスには、従来の大手プラットフォームと異なるリスク要因が存在します。特にデータ保護とプライバシー管理の透明性について、詳細な検証が求められる状況です。
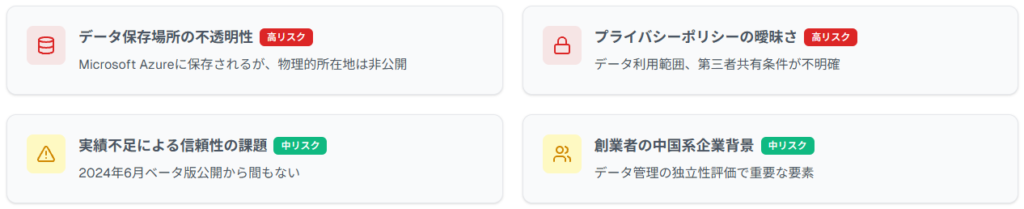
データ保存場所と越境データ移転のリスク
データはMicrosoft Azureに保存されますが、物理的な所在地は明示されていません。米国・シンガポール両国での拠点運営により、データ処理が複数管轄区域を跨ぐ可能性があります。
創業者の中国系企業背景を考慮すると、データの国外移転方針について詳細確認が不可欠です。GDPR等の国際規制対応状況も公開情報では不明確で、欧州企業での利用には慎重な検討を要します。
プライバシーポリシーの透明性不足
検索データはデフォルトでAIモデル訓練に使用され、アカウント設定でのオプトアウトが可能とされています。
しかし、具体的なデータ利用範囲、第三者共有条件、削除要求対応手順が曖昧です。Google Workspace APIは汎用AIモデル開発には使用しないとしていますが、他データソースとの統合処理は詳細不明です。
機密性の高い情報を扱う企業では、これらの不透明性がコンプライアンス違反リスクとなります。
新興サービスとしての実績課題
2024年6月のベータ版公開から間もないサービスで、大規模ビジネス利用の実績は限定的です。セキュリティインシデント対応実績や長期継続性のトラックレコードが不足している状況です。
OpenAI、Anthropic等との戦略的パートナーシップを構築していますが、これらのパートナーシップにおけるデータ共有範囲や各プロバイダーのセキュリティ基準統一性については独自評価が必要です。
創業者の中国系企業バックグラウンド
Eric JingとKay Zhuが共に中国最大手検索企業Baidu元幹部である点は、データ管理の独立性評価で重要な要素となります。Baiduは中国政府規制下で運営され、データローカライゼーションや政府機関への情報提供義務が存在します。
米国法人として運営されていますが、創業者経歴を踏まえた透明性確保と管理プロセスの独立性について継続監視が重要です。
ReAlice株式会社 AIコンサルタントAIモデルの訓練用途や第三者共有に関する情報も現状では不透明であり、特にGDPR等の規制対応には注意が必要です。利用を検討する企業は、公開されている利用規約やポリシーを精査し、必要に応じて独自のデューデリジェンスを実施すべきです。
ビジネス利用で知っておくべきセキュリティ対策

サムスン電子では、従業員がChatGPTに社内ソースコードを入力した結果、機密情報が外部流出するリスクが発覚し、生成AI利用を一時禁止しました 。こうした事例を踏まえ、実効性のある多層防御策の実装が急務となっています。
データ暗号化と多層防御システム
Microsoft Azureクラウド採用により、保存時暗号化(AES-256)と転送時暗号化(TLS 1.2以上)が標準実装されています。ただし、MainFunc社独自の追加暗号化レイヤーやキー管理システムの詳細は非公開です。
企業導入時にはエンドツーエンド暗号化実装状況、暗号鍵管理体制、定期監査実施状況の確認が必要です。
アクセス権限管理とアカウント保護
ユーザー登録時にユーザー名、メールアドレス、パスワード、電話番号が必要ですが、多要素認証(MFA)実装状況は明示されていません。香港の多国籍企業では、AIで合成された同僚の姿を悪用したビデオ通話詐欺により約38億円が送金される事件が発生しました。
企業利用ではActive Directory連携、SSOサポート、役割ベースアクセス制御(RBAC)の技術仕様確認が不可欠です。最小権限原則に基づくアクセス制御と定期的な権限レビューの実施が推奨されます。
AIファクトチェック機能と誤情報対策
Claude、OpenAI GPT等の複数LLMモデル組み合わせにより、単一モデルによる偏見リスクを軽減する設計です。複数モデルの出力比較検証でハルシネーション(AI幻覚)リスクの低減を図っています。
重要な意思決定には人的検証が不可欠で、MITRE ATLASフレームワークが定義するデータポイゾニング、モデル推論攻撃等への継続的対策評価が必要です。
リアルタイム脅威検知システム
標準的な不正利用防止やシステム監視を実装していると記載されていますが、具体的な脅威検知技術は非公開です。
Salesforceでは、AIによりIPアドレスやアクセス元位置情報をリアルタイム分析し、普段と異なる地域からのアクセスを自動検知してセキュリティレベルを引き上げるシステムを運用しています。
企業導入時には異常検知システム、攻撃パターン分析、インシデント対応自動化の実装確認と、自社SOCとの連携可能性評価が重要です。
ReAlice株式会社 AIコンサルタント複数モデルを用いた出力比較はハルシネーション低減に有効ですが、最終判断には人のレビュー工程を組み込むべきです。セキュリティ面では、アクセス元や操作傾向の異常検知を含む多層的な脅威対策が求められます。
企業導入前に確認すべきコンプライアンス要件
韓国サムスン電子の事例では、従業員が業務効率化のために社外秘情報をChatGPTに入力し、データが外部サーバーに送信される事態が発生しました。こうしたリスクを回避するため、法的要件との適合性を慎重に評価する必要があります。
法的根拠の明確化とデータ主体同意の取得状況を評価
データ分類制度とGensparkの利用範囲を明確化
データ責任者の任命とAI利用特化管理プロセスの確立
GDPR等国際規制への対応状況
AIモデル学習・利用におけるGDPR適用の規制強化が進行中です。検索データがデフォルトでAIモデル訓練に使用されますが、GDPR第6条に基づく処理の法的根拠について十分な説明がありません。
アイルランドデータ保護委員会がGoogleのAIモデル開発に対して調査を実施した事例のように、EU域内データの学習利用には事前の適切な保護措置とデータ主体の同意取得が必要です。個人データ処理を防ぐ堅牢なフィルタリング機能の実装確認が重要です。
社内規定との整合性チェックポイント
データ分類制度(公開、社内限定、機密、極秘)とGensparkでの利用可能範囲の明確化が第一歩となります。アカウント削除から30日以内にデータを削除すると記載されていますが、AIモデル学習に使用されたデータの完全削除可能性は不明確です。
OpenAIやAnthropicへのクエリ送信が行われるため、各プロバイダーのデータ処理契約内容確認が必要です。金融業界のPCI DSS、医療業界のHIPAA、製造業のITAR等、業界固有規制要件との適合性について個別評価が求められます。
データガバナンス体制の構築方法
データ責任者(Data Steward)の任命と、AI利用特化管理プロセスの確立が必要です。NIST AI Risk Management Frameworkの4段階アプローチ(Map、Measure、Manage、Govern)に基づくリスク評価マトリックス作成と定期見直しが重要です。
Gensparkへの入力データ前処理、出力結果検証、誤情報・偏見検出機能の組み込みが推奨されます。組織固有のリスクアセスメント実施と継続監視体制構築が効果的です。
ReAlice株式会社 AIコンサルタント社内データ分類との連携や、外部ベンダーとの契約条件の精査も現場実装に直結します。さらに、AI活用に特化したガバナンス体制の構築が継続的なセキュリティ確保と信頼担保に繋がります。
Gensparkと競合サービスの安全性比較
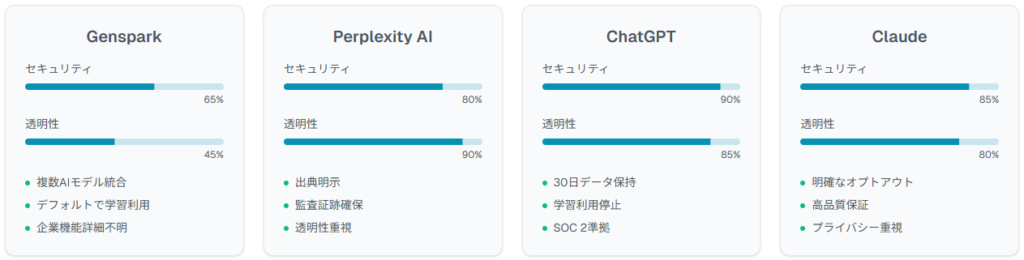
AI検索市場では各サービスのセキュリティアプローチに大きな差異が存在します。OpenAI自身もChatGPTでバグによるチャット履歴表示問題を経験しており、各プラットフォームの実績と透明性を比較検証することが重要です。
Perplexity AIとの機能・セキュリティ比較
Perplexity AIは回答に常に出典が明示される特徴を持ち、情報の透明性と信頼性確認が容易です。Gensparkは複数AIモデル統合による情報提供に特化していますが、情報源の透明性で劣る場合があります。
Perplexityは出典による監査証跡確保機能を提供しており、企業導入での優位点となります。
Claude・ChatGPTとの透明性の違い
ChatGPTは2024年更新のデータ保持ポリシーにより、API利用時のデータ保持期間を30日に短縮し、デフォルト学習利用を停止しています。AnthropicのClaudeも同様に、ユーザーデータの学習利用に対する明確なオプトアウト機能を提供しています。
これに対しGensparkはデフォルトで検索データをAI学習に使用する設定で、透明性にギャップが存在します。ChatGPTの多要素認証、APIキー管理、使用量監視機能と比較すると、Gensparkの企業向けセキュリティ機能は詳細が不明確です。
料金プランごとのセキュリティ機能差
現在のGensparkは基本無料プランを中心とした提供で、企業向け有料プランのセキュリティ機能詳細は非公開です。ChatGPT EnterpriseではSOC 2 Type II準拠、SAML SSO、データ処理協定(DPA)、管理コンソール等の企業機能を提供しています。
Claude Proでは優先アクセス、拡張利用制限、高品質保証が含まれます。Perplexity Proはより多くのクエリ処理能力とプレミアムモデルアクセスを提供しています。
ReAlice株式会社 AIコンサルタントAI検索ツール選定においては、回答の正確性だけでなく情報源の明示や利用データの扱いが重要な判断軸になります。
企業導入では、機能比較に加え料金プラン別のセキュリティ差異や規約内容の精査が欠かせません。
安全にGensparkを活用するための実践ガイド
サムスン電子、OpenAI、香港多国籍企業などで発生したAI関連セキュリティインシデントを踏まえ、段階的アプローチによる実効性のあるリスク管理策が不可欠です。
- 機密情報の入力制限による情報漏洩防止
- 段階的導入によるリスク最小化
- 社内ポリシーの明確な策定
- インシデント対応手順の事前準備
機密情報入力時の注意事項
データ分類に基づく厳格な制御が必要です。個人情報、営業秘密、技術仕様書等の機密情報は原則入力禁止とし、公開情報または匿名化済みデータのみを使用します。
検索クエリがデフォルトでAI学習に使用されるため、競合他社に知られたくない市場調査内容や製品開発情報の入力は避けるべきです。医療機関の患者情報、金融機関の顧客財務情報、製造業の製品設計データなど、業界固有の機密情報についても同様の制限を適用します。
入力前のデータサニタイゼーション(個人識別子除去、数値の丸め処理等)実施と、組織データ分類ポリシーに準拠した利用ガイドライン策定が推奨されます。
段階的導入アプローチの設計
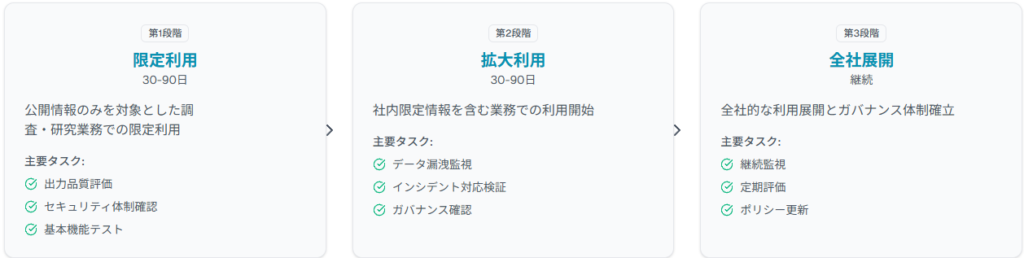
社内ポリシー策定のポイント
技術的制約と業務要件のバランス確保が重要です。利用目的では、Gensparkの使用許可業務範囲(市場調査、技術動向分析、顧客サポート等)を具体的に定義します。データ取扱規則では入力可能データ種類、匿名化要件、出力結果検証方法を詳細規定します。責任体制では、AI利用責任者、データ管理者、セキュリティ監査者の役割分担を明記し、インシデント発生時のエスカレーション手順を定めます。定期見直しプロセスでは四半期ごとのポリシー有効性評価と、技術動向に応じた更新手順確立が推奨されます。
インシデント発生時の対応手順
AI利用特化インシデント対応計画の策定が必要です。データ漏洩疑い時には24時間以内にGensparkの利用を一時停止し、影響範囲特定と証拠保全を実施します。誤情報による業務影響発生時には出力結果検証プロセスを強化し、人的チェック機能を追加します。
システム障害時には代替手段(従来検索エンジン、内部データベース等)への切り替え手順を事前準備します。各インシデント対応後には根本原因分析(RCA)を実施し、再発防止策をポリシーに反映する継続改善プロセスを確立します。
ReAlice株式会社 AIコンサルタントGensparkのように検索内容がモデル学習に活用される設計では、入力内容の厳格な管理が重要です。
インシデント発生時の即時対応や復旧手順の整備も信頼性維持に不可欠です。
ビジネス導入の判断基準と意思決定フロー
サムスン電子が生成AI利用を一時禁止せざるを得なくなった事例や、香港企業での38億円送金詐欺事件を踏まえ 、体系的なリスク評価と費用対効果分析に基づく意思決定プロセスが必要です。
リスク評価マトリックスの作成方法
確率と影響度を軸とした5×5マトリックスの活用が効果的です。データセキュリティリスクでは、機密情報の意図しない学習利用(高確率・高影響)、第三者へのデータ流出(低確率・極高影響)、アクセス権限の不適切管理(中確率・高影響)を評価対象とします。
コンプライアンスリスクではGDPR違反(中確率・極高影響)、業界規制抵触(低確率・高影響)、内部監査指摘(高確率・中影響)を考慮します。
運用リスクではサービス継続性問題(中確率・中影響)、出力品質劣化(高確率・低影響)、ユーザーの過度な依存(高確率・中影響)を評価項目に含めます。各リスク項目に対し現在の制御措置、残存リスクレベル、追加対策必要性を四半期ごと見直すプロセスが重要です。
- データセキュリティリスク:機密情報漏洩、不正アクセス
- コンプライアンスリスク:規制違反、監査指摘
- 運用リスク:サービス継続性、品質劣化
- 技術リスク:ハルシネーション、依存性
ROI算出とコスト対効果の検証
直接的コスト削減と生産性向上の両面から分析を行います。コスト削減効果では従来調査業務時間(市場リサーチャーの月40時間)から、Genspark活用後(月10時間)への短縮による人件費削減を算出します。生産性向上効果では意思決定迅速化による機会創出、高品質分析結果による戦略精度向上を貨幣価値換算します。
導入コストにはライセンス費用、社内研修費用、セキュリティ強化投資、ポリシー策定費用を含めます。投資回収期間(ROI)目標を12-24ヶ月に設定し、四半期ごと実績評価により継続可否を判断します。
導入可否を決める5つのチェック項目
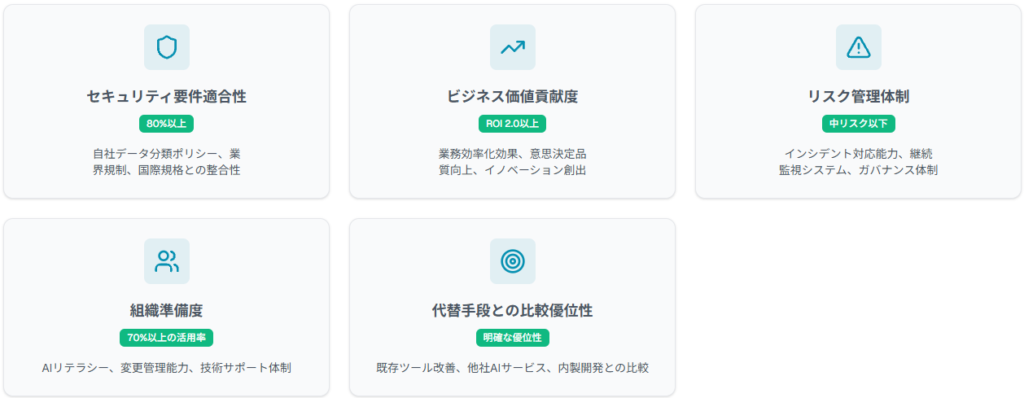
自社データ分類ポリシー、業界規制、国際規格(ISO 27001等)との整合性を評価し、80%以上の適合率を導入基準とします。
具体的業務効率化効果、意思決定品質向上、イノベーション創出への寄与を定量評価し、投資対効果比2.0以上を目標とします。
インシデント対応能力、継続監視システム、ガバナンス体制整備状況を評価し、リスクレベルが許容範囲内(中リスク以下)であることを確認します。
ユーザーのAIリテラシー、変更管理能力、技術サポート体制を評価し、70%以上のユーザーが適切に活用できる環境を確保します。
既存ツール改善、他社AIサービス採用、内製開発等の選択肢と比較し、Gensparkの優位性を客観検証します。これら5項目すべてで基準をクリアした場合のみ、本格導入に進むことを推奨します。
ReAlice株式会社 AIコンサルタント業務効率化の効果は人件費や意思決定スピードなど、具体的な指標で検証する視点が重要です。
本格導入の前提として、他ツールとの比較優位性を客観的に示すこともエンジニアリング観点からは推奨されます。
よくある質問
企業導入検討時に特に頻繁に寄せられるセキュリティ・プライバシー関連の疑問について、現在の公開情報に基づいて回答します。
Gensparkのデータは海外に保存されるのか?
ユーザーデータはMicrosoft Azureクラウドプラットフォームに保存されると明記されていますが、具体的なデータセンター所在地は非公開です。米国本社とシンガポール拠点の両方を持つため、データ処理が複数管轄区域にまたがる可能性があります。
データローカライゼーション要件がある企業は、事前にMainFunc社への具体的データ保存場所の確認と、必要に応じたデータ処理協定(DPA)締結を検討すべきです。
入力した情報がAI学習に使われる可能性は?
検索データはデフォルトでAIモデル改善・訓練に使用されます。ログインユーザーは設定ページで「AI目的のデータ収集」を無効化可能ですが、未ログインユーザーはこの機能を利用できません。
第三者AIプロバイダー(Anthropic等)へのクエリ送信も行われるため、これらのプロバイダーのデータ利用ポリシーも間接的に適用される可能性があります。企業利用では契約による学習利用の完全除外を求めることが推奨されます。
無料プランと有料プランでセキュリティに差はあるか?
現在は主に無料プランでのサービス提供で、有料プランの詳細仕様は非公開です。ChatGPTやClaudeなどの競合では、有料プランでより高度なセキュリティ機能(SOC 2準拠、SSO連携、データ処理協定等)を提供しています。
企業導入検討時には、事前にMainFunc社へ企業向けプランの機能詳細とセキュリティSLA提供可能性について確認が必要です。
他社からGensparkに乗り換える際の注意点は?
既存AI検索サービスからの移行時にはデータ移行とセキュリティ設定見直しが重要です。移行前サービスからのデータエクスポート後、Gensparkでの取扱方針と照合してセキュリティレベル維持を確認します。ユーザーアクセス権限の再設定と、多要素認証等セキュリティ機能の設定を実施します。
Perplexity AIからは引用機能品質変化、ChatGPTからは対話機能の違い、Claudeからは長文処理能力変化を事前評価することが推奨されます。
セキュリティ事故が発生した場合の補償制度はあるか?
現在の利用規約やプライバシーポリシーでは、データセキュリティ事故に対する具体的補償制度や責任範囲の詳細記載がありません。一般的免責事項として、データ送信や電子保存方法が100%安全でないことを明記し、絶対的セキュリティを保証しない旨が記載されています。
企業利用ではサイバー保険適用範囲確認、データ処理協定による責任分担明確化、SLAによる補償条件設定を検討することが重要です。機密性の高いデータを扱う企業では、事前にMainFunc社との個別責任制限協定や補償条項を含む契約締結を検討すべきです。
